Реплики для чтения
Реплики для чтения позволяют создать одну или несколько копий вашей основной базы данных Managed Postgres. Эти реплики непрерывно синхронизируются с основной базой данных, используя встроенную репликацию PostgreSQL, чтобы своевременно получать все изменения.
Чтобы управлять репликами для чтения, нажмите значок редактирования в вашем хранилище:
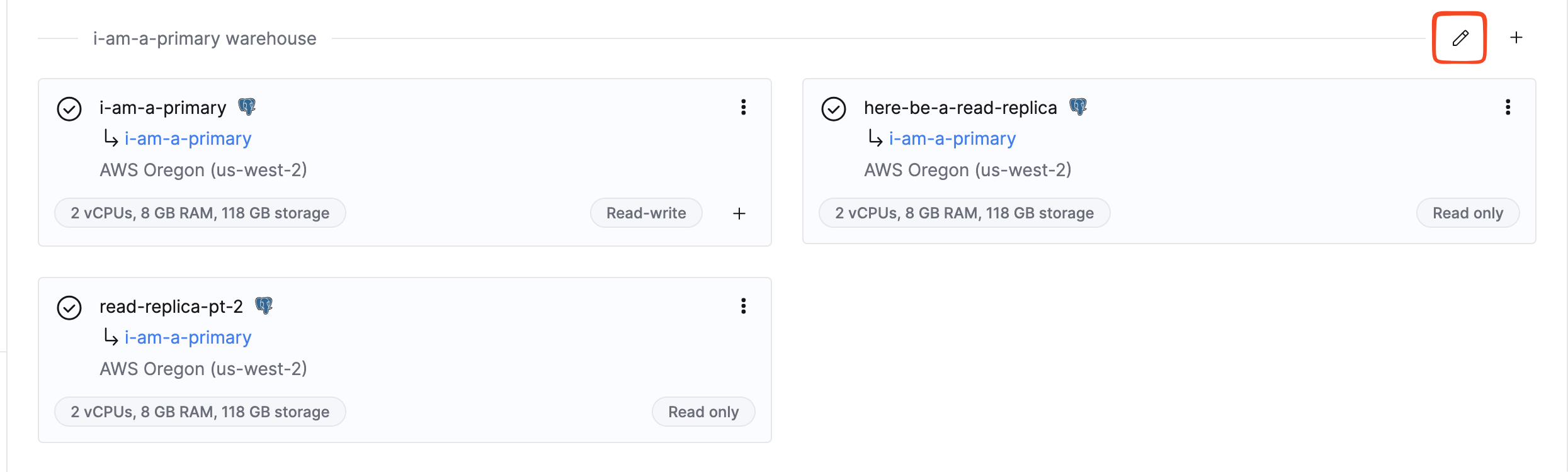
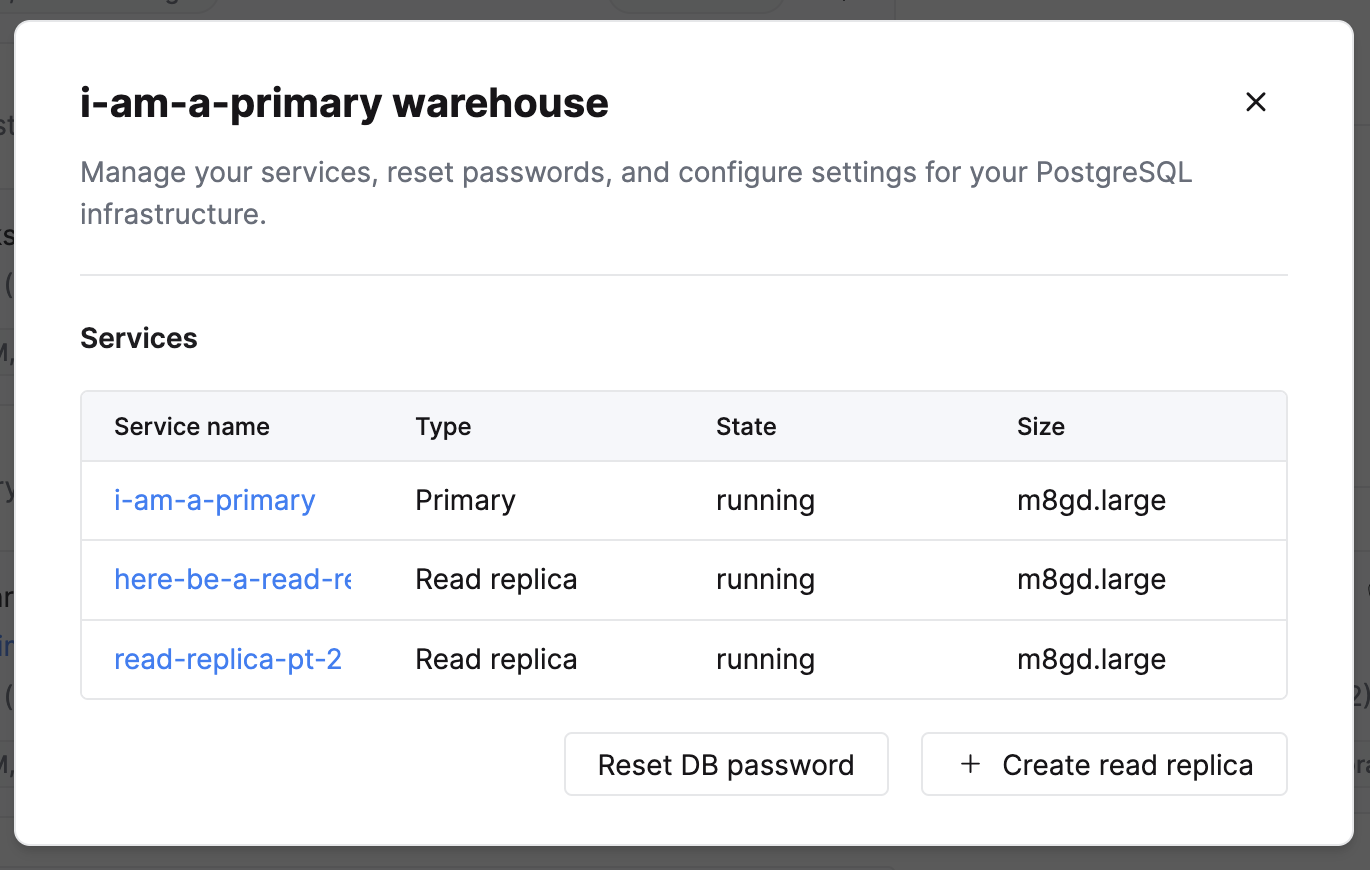
Откроется диалоговое окно хранилища, где вы можете просмотреть существующие сервисы и создать новые реплики для чтения:
Зачем нужны реплики для чтения
Масштабируемость
Реплики для чтения позволяют горизонтально масштабировать базу данных за счет распределения ресурсоемких операций чтения между несколькими выделенными экземплярами. Это особенно ценно для отчетных запросов, аналитической обработки и дашбордов в реальном времени, которые в противном случае конкурировали бы с вашей продакшн‑нагрузкой за ресурсы.
Изоляция
Направляя аналитические и BI‑запросы на реплики, вы сохраняете основной экземпляр сосредоточенным на операциях записи и критически важных транзакционных нагрузках, обеспечивая его высокую отзывчивость. Такое разделение улучшает общую производительность системы и предсказуемость. Это также означает, что вам не нужно предоставлять аналитическим и отчётным инструментам права на запись — они могут безопасно работать с репликой, не рискуя случайно изменить данные.
Обеспечение непрерывности бизнеса
Реплики для чтения могут играть ключевую роль в восстановлении после сбоев. Если основная база данных выходит из строя, реплику для чтения можно перевести в роль основной, что минимизирует время простоя и потерю данных. Это обеспечивает дополнительный уровень отказоустойчивости сверх резервов высокой доступности.
Как работают реплики для чтения
Реплики для чтения в Managed Postgres используют архитектуру доставки WAL, а не потоковую репликацию. Такое архитектурное решение минимизирует влияние на основную базу данных.
Доставка WAL из объектного хранилища
Когда ваша основная база данных обрабатывает транзакции, она генерирует записи журнала предзаписи (Write-Ahead Log, WAL). Эти сегменты WAL непрерывно архивируются в объектное хранилище (S3). Реплики для чтения загружают и применяют эти сегменты WAL из объектного хранилища, чтобы оставаться синхронизированными с основной базой данных.
Эта архитектура отличается от резервных узлов высокой доступности, которые используют потоковую репликацию с прямым подключением к основной базе данных.
Почему мы выбрали этот подход
Мы намеренно спроектировали реплики только для чтения так, чтобы они потребляли WAL из объектного хранилища, а не подключались напрямую к primary как потоковые резервные серверы. Такой подход обеспечивает полную изоляцию между репликами только для чтения и вашей основной базой данных:
- Нулевые накладные расходы на репликацию для primary: реплики только для чтения не поддерживают потоковые подключения к primary, поэтому они не создают дополнительной нагрузки по CPU, памяти или сети на ваши критически важные рабочие нагрузки.
- Независимое масштабирование: вы можете добавлять или удалять реплики только для чтения без какого-либо влияния на производительность primary.
- Сетевая изоляция: реплики только для чтения работают в собственной сетевой среде с отдельными конечными точками подключения.
Характеристики лага репликации
Обратной стороной такой архитектуры является лаг репликации. Сегменты WAL архивируются с основного сервера (primary) через регулярные интервалы (обычно каждые 60 секунд или когда сегмент заполняется, в зависимости от того, что наступит раньше). Это означает, что реплики для чтения в нормальных условиях могут отставать от primary на несколько десятков секунд.
Для большинства сценариев масштабирования чтения — отчётность, аналитика, дашборды — такой лаг приемлем. Если вашему приложению требуется чтение, близкое к реальному времени, рассмотрите, можно ли направлять запросы на primary или же модель eventual consistency в пределах этого временного окна соответствует вашим требованиям.
